Comment concevoir un système stéréo intégré personnalisé pour la perception de la profondeur

Il existe différentes options de capteurs 3D pour développer des systèmes de perception de la profondeur, notamment la vision stéréoscopique avec des caméras, un système lidar et des capteurs de temps de vol. Chaque option a ses forces et ses faiblesses. Un système stéréo est généralement peu coûteux, suffisamment robuste pour une utilisation en extérieur et peut fournir un nuage de points de couleur haute résolution.
Il existe aujourd’hui divers systèmes stéréo prêts à l’emploi sur le marché. En fonction de facteurs tels que la précision, la référence, le champ de vision et la résolution, il arrive que les ingénieurs système aient besoin de construire un système personnalisé pour répondre aux exigences spécifiques des applications.
Dans cet article, nous décrivons d’abord les principales parties d’un système de vision stéréoscopique, puis nous fournissons des instructions sur la fabrication de votre propre caméra stéréo personnalisée à l’aide de composants matériels prêts à l’emploi et de logiciels open source. Cette configuration étant axée sur l’intégration, elle calcule une carte de profondeur de n’importe quelle scène en temps réel, sans avoir besoin d’un ordinateur hôte. Dans un article séparé, nous discutons de la manière de créer un système stéréo personnalisé à utiliser avec un ordinateur hôte lorsque l’espace représente moins une contrainte.
Une autre application qui peut grandement bénéficier d’un tel système de traitement d’intégration est la détection d’objet. Grâce aux progrès de l’apprentissage en profondeur, il est devenu relativement facile d’ajouter la détection d’objet aux applications, mais le besoin de ressources GPU dédiées est prohibitif pour de nombreux utilisateurs. Dans cet article, nous expliquons également comment ajouter l’apprentissage en profondeur à votre application de vision stéréoscopique sans avoir besoin d’un GPU hôte onéreux. Nous avons divisé les exemples de code et les sections de cet article en vision stéréoscopique et apprentissage en profondeur. Si votre application ne nécessite pas d’apprentissage en profondeur, n’hésitez pas à sauter les sections sur l’apprentissage en profondeur.
Présentation de la vision stéréoscopique
La vision stéréoscopique est l’extraction d’informations 3D à partir d’images numériques en comparant les informations d’une scène de deux points de vue. Les positions relatives d’un objet dans deux plans d’image fournissent des informations sur la profondeur de l’objet à partir de la caméra.
Un aperçu d’un système de vision stéréoscopique est présenté à la Figure 1 et comprend les étapes clés suivantes :
- Étalonnage : L’étalonnage de la caméra fait référence à la fois aux paramètres intrinsèque et extrinsèque. L’étalonnage intrinsèque détermine le centre de l’image, la distance focale et les paramètres de distorsion, tandis que l’étalonnage extrinsèque détermine les positions 3D des caméras. Il s’agit d’une étape cruciale dans de nombreuses applications de vision par ordinateur, en particulier lorsque des informations métriques sur la scène, telles que la profondeur, sont requises. Nous aborderons l’étape d’étalonnage en détail à la Section 5 ci-dessous.
- Rectification : La rectification stéréo fait référence au processus de reprojection de plans d’image sur un plan commun parallèle à la ligne entre les centres de la caméra. Après rectification, les points correspondants se trouvent sur la même ligne, ce qui réduit considérablement le coût et l’ambiguïté de la correspondance. Cette étape est effectuée dans le code fourni pour construire votre propre système.
- Correspondance stéréo : Il s’agit du processus de correspondance des pixels entre les images de gauche et de droite, ce qui génère des images de disparité. L’algorithme de Correspondance semi-globale (SGM, Semi-Global Matching) sera utilisé dans le code fourni pour construire votre propre système.
- Triangulation : La triangulation fait référence au processus de détermination d’un point dans l’espace 3D compte tenu de sa projection sur les deux images. L’image de disparité sera convertie en un nuage de points 3D.
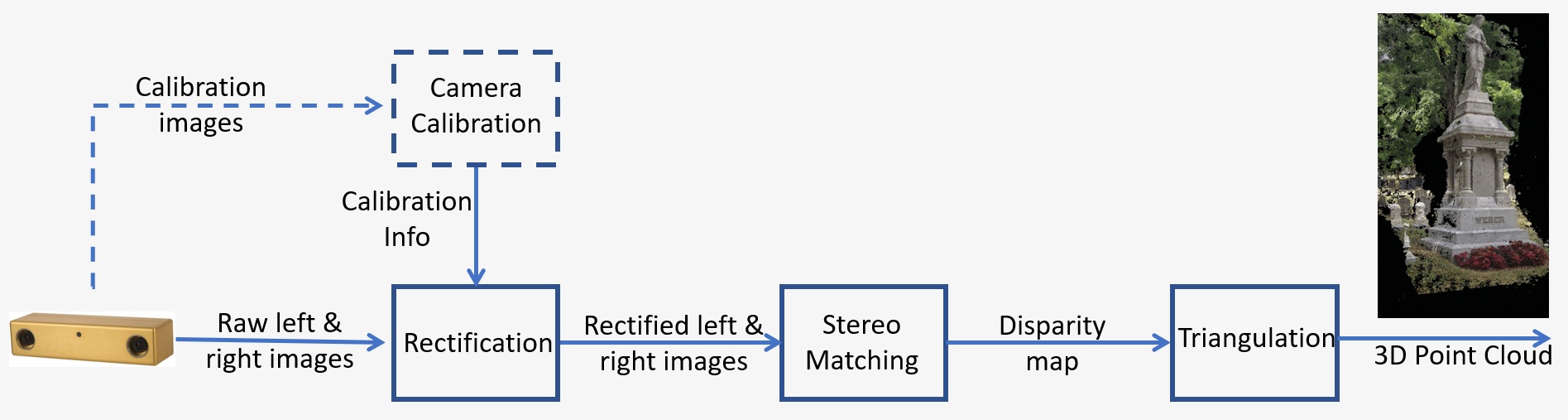
Figure 1 : Présentation d’un système de vision stéréoscopique
Vue d’ensemble de l’apprentissage en profondeur
L’apprentissage en profondeur est un sous-domaine de l’apprentissage automatique qui traite des algorithmes basés sur la structure et le fonctionnement du cerveau. Il tente d’imiter la capacité d’apprentissage du cerveau humain. Les algorithmes d’apprentissage en profondeur peuvent effectuer efficacement des opérations complexes telles que la reconnaissance d’objets, la classification, la segmentation, etc. L’apprentissage en profondeur permet notamment aux machines de reconnaître des personnes et des objets dans les images qui lui sont fournies. L’application particulière qui nous intéresse est la détection des personnes. Entraîner vos propres algorithmes d’apprentissage en profondeur requiert une grande quantité de données d’entraînement identifiées, mais les modèles préformés en libre accès facilitent le développement de ces applications.
L’apprentissage en profondeur nécessite également des GPU de haute performance, mais la solution Quartet pour TX2 offre toutes les capacités d’un GPU de plus grande taille pour une fraction du facteur de forme et de la consommation d’énergie. L’exécution des modèles d’apprentissage en profondeur sur le TX2 permet également de bénéficier de plus de mobilité et constitue un atout parfait pour les robots mobiles qui doivent détecter les personnes tout en restant à l’écart.
Exemple de conception
Passons en revue un exemple de conception de système stéréo. Voici les exigences pour une application robotisée mobile dans un environnement dynamique avec des objets en mouvement rapide. La scène d’intérêt mesure 2 m, la distance entre les caméras et la scène est de 3 m et la précision souhaitée est de 1 cm à une distance de 3 m.
Vous pouvez consulter cet article pour plus de détails sur la précision stéréo. L’erreur de profondeur est donnée par : ΔZ=Z²/Bf * Δd qui dépend des facteurs suivants :
- Z est la plage
- B est la référence
- f est la distance focale en pixels, qui est liée au champ de vision de la caméra et à la résolution de l’image
Il existe différentes options de conception qui peuvent répondre à ces exigences. En fonction de la taille de la scène et des exigences de distance ci-dessus, nous pouvons déterminer la distance focale de l’objectif pour un capteur spécifique. Avec la référence, nous pouvons utiliser la formule ci-dessus pour calculer l’erreur de profondeur attendue à 3 m, afin de vérifier qu’elle répond aux exigences de précision.
Deux options sont présentées à la Figure 2, en utilisant des caméras à résolution inférieure avec une référence plus longue ou des caméras à résolution supérieure avec une référence moins longue. La première option est une caméra plus grande, mais qui a un besoin de calcul plus faible, tandis que la deuxième option est une caméra plus compacte, mais qui a un besoin de calcul plus élevé. Pour cette application, nous avons choisi la deuxième option, car une taille compacte est plus souhaitable pour le robot mobile et nous pouvons utiliser la solution intégrée Quartet pour TX2 qui dispose d’un GPU puissant intégré pour répondre aux besoins de traitement.

Figure 2 : Options de conception de système stéréo pour un exemple d’application
Configuration matérielle
Pour cet exemple, nous montons deux caméras de 1,6 MP version carte Blackfly S à l’aide du capteur à obturateur global Sony Pregius IMX273 sur une barre imprimée en 3D à une référence de 12 cm. Les deux caméras ont des objectifs similaires à monture en S de 6 mm. Les caméras se connectent à la solution intégrée Quartet pour carte de support personnalisée TX2 à l’aide de deux câbles FPC. Pour synchroniser les caméras gauche et droite afin de capturer des images en même temps, un câble de synchronisation est fabriqué pour connecter les deux caméras. La figure 3 montre les vues avant et arrière de notre système stéréo intégré personnalisé.

Figure 3 : Vues avant et arrière de notre système stéréo intégré personnalisé
Le tableau suivant répertorie tous les composants matériels :
|
Composant |
Description |
Quantité |
Lien |
|
ACC-01-6005 |
Support Quartet avec module TX2 8 Go |
1 |
https://www.flir.com/products/quartet-embedded-solution-for-tx2/ |
|
BFS-U3-16S2C-BD2 |
1,6 MP, 226 images par seconde, Sony IMX273, couleur |
2 |
|
|
ACC-01-5009 |
Monture en S et filtre IR pour caméras niveau de carte couleur BFS |
2 |
|
|
BW3M60B-1000 |
Objectif à monture en S de 6 mm |
|
http://www.boowon.co.kr/site/ |
|
ACC-01-2401 |
Câble FPC de 15 cm pour niveau carte Blackfly S |
2 |
https://www.flir.com/products/15-cm-fpc-cable-for-board-level-blackfly-s/ |
|
XHG302 |
Dissipateur thermique actif NVIDIA® Jetson™ TX2/TX2 4 Go/TX2i |
1 |
https://connecttech.com/product/nvidia-jetson-tx2-tx1-active-heat-sink/ |
|
Câble de synchronisation (fabriquez le vôtre) |
1 |
||
|
Barre de montage (fabriquez la vôtre) |
1 |
Les deux objectifs doivent être ajustés pour que les caméras soient mises au point sur la plage de distances requise par votre application. Serrez la vis (encerclée en rouge sur la Figure 4) située sur chaque objectif pour maintenir la mise au point.

Figure 4 : Vue latérale de notre système stéréo montrant la vis de l’objectif
Configuration logicielle requise
a. Spinnaker
La bibliothèque SDK Spinnaker de Teledyne FLIR est préinstallée sur vos solutions intégrées Quartet pour TX2. Spinnaker est requis pour communiquer avec les caméras.
b. OpenCV 4.5.2 avec prise en charge CUDA
L’OpenCV version 4.5.1 ou une version plus récente est requise pour SGM, l’algorithme de correspondance stéréo que nous utilisons. Téléchargez le fichier zip contenant le code de cet article et décompressez-le dans le dossier StereoDepth. Le script pour installer OpenCV est OpenCVInstaller.sh. Saisissez les commandes suivantes dans un terminal :
- cd ~/StereoDepth
- chmod +x OpenCVInstaller.sh
- ./OpenCVInstaller.sh
Le programme d’installation vous demandera de saisir votre mot de passe administrateur. Le programme d’installation commencera à installer OpenCV 4.5.2. Le téléchargement et la création d’OpenCV peuvent prendre quelques heures.
c. Jetson-inference (si un apprentissage en profondeur est nécessaire)
Jetson-inference est une bibliothèque de source ouverte de NVIDIA qui peut être utilisée pour l’apprentissage en profondeur accéléré par le GPU sur les appareils Jetson, comme le TX2. La bibliothèque utilise le TensorRT SDK qui facilite l’inférence haute performance sur les GPU de NVIDIA. Jetson-inference fournit à l’utilisateur un ensemble de modèles d’apprentissage en profondeur préformés et prêts à l’emploi, ainsi que le code permettant de déployer ces modèles à l’aide de TensorRT. Pour installer jetson-inference, tapez les commandes suivantes dans un terminal :
- cd ~/StereoDepth
- chmod +x InferenceInstaller.sh
- ./InferenceInstaller.sh
Étalonnage
Le code permettant de capturer des images stéréo et de les calibrer se trouve dans le dossier « Étalonnage ». Utilisez l’interface utilisateur graphique SpinView pour identifier les numéros de série des caméras gauche et droite. Pour nos paramètres, la caméra de droite est la caméra maître et la caméra de gauche est l’esclave. Copiez les numéros de série des caméras maître et esclave dans le fichier grabStereoImages.cpp aux lignes 60 et 61. Créez l’exécutable à l’aide des commandes suivantes dans un terminal :
- cd ~/StereoDepth/Calibration
- mkdir build
- mkdir -p images/{left, right}
- cd build
- cmake ..
- make
Imprimez le motif à damier à partir de ce lien et fixez-le à une surface plane pour l’utiliser comme cible d’étalonnage. Pour de meilleurs résultats lors de l’étalonnage, dans SpinView, réglez Exposition Auto (Exposition automatique) sur Off (Désactivé) et réglez l’exposition de sorte que le motif à damier soit net et que les carrés blancs ne soient pas surexposés, comme illustré à la Figure 5. Une fois les images d’étalonnage collectées, le gain et l’exposition peuvent être réglés sur auto dans SpinView.
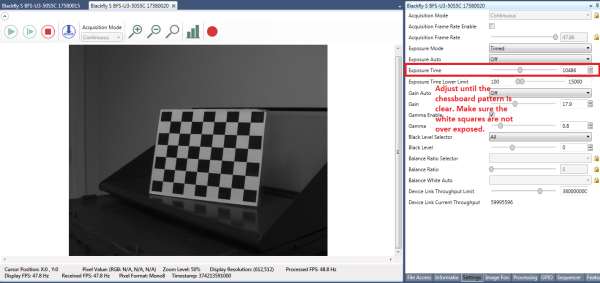
Figure 5 : Paramètres de l’interface utilisateur graphique SpinView
Pour commencer à collecter les images, saisissez
- ./grabStereoImages
Le code doit commencer à collecter des images à une fréquence d’environ 1 image/seconde. Les images de gauche sont stockées dans le dossier images/left (images/gauche) et les images de droite sont stockées dans le dossier images/right (images/droite). Déplacez la cible de manière à ce qu’elle apparaisse dans chaque coin de l’image. Vous pouvez faire pivoter la cible, prendre des images de près et de loin. Par défaut, le programme capture 100 paires d’images, mais peut être modifié avec un argument de ligne de commande :
- ./grabStereoImages 20
Cela ne collectera que 20 paires d’images. Veuillez noter que cela remplacera toutes les images précédemment enregistrées dans les dossiers. Certains exemples d’images d’étalonnage sont illustrées à la Figure 6.

Figure 6 : Exemples d’images d’étalonnage
Après avoir collecté les images, exécutez le code Python d’étalonnage en saisissant :
- cd ~/StereoDepth/Calibration
- python cameraCalibration.py
Cela générera deux fichiers appelés « intrinsics.yml » et « extrinsics.yml » qui contiennent les paramètres intrinsèque et extrinsèque du système stéréo. Le code suppose un damier carré de 30 mm par défaut, mais peut être modifié si nécessaire. À la fin de l’étalonnage, l’erreur moyenne quadratique RMS s’affiche, indiquant la qualité de l’étalonnage. L’erreur RMS typique pour un bon étalonnage doit être inférieure à 0,5 pixel.
Carte de profondeur en temps réel
Le code permettant de calculer la disparité en temps réel se trouve dans le dossier « Profondeur ». Copiez les numéros de série des caméras dans les fichiers live_disparity.cpp lignes 230 et 231. Créez l’exécutable à l’aide des commandes suivantes dans un terminal :
- cd ~/StereoDepth/Depth
- mkdir build
- cd build
- cmake ..
- make
Copiez les fichiers « intrinsics.yml » et « extrinsics.yml » obtenus lors de l’étape de calibrage dans ce dossier. Pour exécuter la démonstration de la carte de profondeur en temps réel, saisissez
- ./live_disparity
Cela affiche l’image de la caméra de gauche (image brute non corrigée) et la carte de profondeur (notre sortie finale). Certains exemples de sorties sont illustrés à la Figure 7. La distance de la caméra est codée par couleur selon la légende à droite de la carte de profondeur. La région noire dans la carte de profondeur signifie qu’aucune donnée de disparité n’a été trouvée dans cette région. Grâce au GPU NVIDIA Jetson TX2, il est possible d’exécuter jusqu’à 5 images/seconde à une résolution de 1 440 × 1 080 et jusqu’à 13 images/seconde à une résolution de 720 × 540.
Pour voir la profondeur à un point particulier, cliquez sur ce point dans la carte de profondeur et la profondeur sera affichée, comme illustré dans le dernier exemple de la Figure 7.

Figure 7 : Exemples d’images de la caméra de gauche et carte de profondeur correspondante. La carte de profondeur inférieure montre également la profondeur à un point particulier.
Détection de personnes
Nous utilisons DetectNet fourni par Jetson-inference pour détecter les humains dans une image. DetectNet propose des options permettant de sélectionner l’architecture du modèle d’apprentissage en profondeur pour la détection d’objets. Nous utilisons l’architecture Single Shot Detection (SSD) avec une structure MobileNetV2 pour optimiser à la fois la vitesse et la précision. Lors de la première exécution de la démo, TensorRT crée un moteur numéroté pour optimiser davantage la vitesse d’inférence, ce qui peut prendre quelques minutes. Cette machine est automatiquement sauvegardée dans des fichiers pour des exécutions ultérieures. L’architecture utilisée est assez efficace et on peut s’attendre à environ 50 fps pour l’exécution du module de détection. Le code pour la capacité de détection des personnes ainsi que la profondeur stéréoscopique en temps réel se trouve dans le dossier « DepthAndDetection ». Copiez les numéros de série des caméras dans le fichier live_disparity.cpp aux lignes 271 et 272. Construisez le fichier exécutable en utilisant les commandes suivantes dans un terminal :
- cd ~/StereoDepth/DepthAndDetection
mkdir
buildcd
buildcmake ..
make
Copiez les fichiers « intrinsics.yml » et « extrinsics.yml » obtenus lors de l’étape d’étalonnage dans ce dossier. Pour lancer la démo de la carte de profondeur en temps réel, tapez
- ./live_disparity
Deux fenêtres montrant les images en couleur rectifiées à gauche et la carte de profondeur s’affichent. La carte de profondeur est codée en couleur pour une meilleure visualisation de la carte de profondeur. Les deux fenêtres ont des matrices de caractère qui entourent les personnes dans l’image et affichent la distance moyenne entre la personne et la caméra. Grâce au traitement stéréoscopique et à l’inférence par apprentissage en profondeur, la démo tourne à environ 4 fps à une résolution de 1440 × 1080 et jusqu’à 11,5 fps pour une résolution de 720 × 540.

Figure 1 : Exemple d’images de la caméra gauche et de la carte de profondeur correspondante. Toutes les images montrent la personne détectée à l’image et la distance de la personne par rapport à la caméra.
L’algorithme de détection des personnes est capable de détecter plusieurs personnes même dans des conditions difficiles telles que l’occlusion. Le code calcule les distances de toutes les personnes détectées à l’image, comme indiqué ci-dessous.

Figure 2 : l’image de gauche et la carte de profondeur montrent que plusieurs personnes sont détectées à l’image, ainsi que leur distance respective par rapport à la caméra.
Résumé
L’utilisation de la vision stéréoscopique pour développer une perception de la profondeur présente les avantages suivants : un bon fonctionnement en extérieur, capacité à fournir une carte de profondeur haute résolution et un accès très facile avec des composants prêts à l’emploi à faible coût. Selon les exigences, il existe un certain nombre de systèmes stéréo prêts à l’emploi sur le marché. S’il est nécessaire de développer un système stéréo intégré personnalisé, il s’agit d’une tâche relativement simple avec les instructions fournies ici.
Related Articles
-
Tech Note
Comment concevoir un système stéréo intégré personnalisé pour la perception de la profondeur
En savoir plus -
 Systèmes intégrés
Systèmes intégrés
Diffusion en continu de 4 caméras avec petite carte de support : Prototype rapide
Read the Story -
 Systèmes intégrés
Systèmes intégrés
Guide d’intégration des caméras version carte
Read the Story