ディープラーニング推論におけるVPU、GPU、FPGAの比較

はじめに
マシンビジョンにディープラーニングを導入する際に最も重要なのは、推論実行にどんなハードウェアを使用するかということです。グラフィックスプロセッシングユニット(GPU)、フィールドプログラマブルゲートアレイ(FPGA)、および視覚処理装置(VPU)は、それぞれに利点と限界があり、お使いのシステム設計に影響を与えます。この記事では、それぞれの特徴、およびアプリケーションに最適なプラットフォームの選択方法について説明します。
GPU
膨大な演算を並列に処理するGPUのアーキテクチャは、ディープラーニング推論の高速化に最適です。Nvidiaは多額の投資を行い、同社のCUDA(並列コンピューティングアーキテクチャ、Compute Unified Device Architecture)コアでディープラーニングおよび推論を実行できるようにするツールを開発してきました。Google製で人気のTensorFlowが対応するGPUは、NvidiaのCUDAに対応するGPUです。何千ものプロセッサーコアを有しており、自律型車両誘導などの膨大な演算が必要となるタスクや、堅牢とは言えないハードウェアへの学習ネットワークのデプロイなどに適したGPUもあります。電力消費という観点で見ると、GPUは一般的に高い電力を消費します。RTX 2080に必要な電力は225Wですが、Jetson TX2の消費電力は最大でも15Wです。また、GPUが高額であるという問題もあります。RTX 2080の値段は、$800米ドルにも上ります。
FPGA
FPGAは、マシンビジョン業界においては広く使用されています。ほとんどのマシンビジョンカメラおよびフレーム取り込み装置は、FPGAを基本としています。FPGAは、汎用CPUで実行するソフトウェアの柔軟性とプログラム可能性、特定用途向け集積回路(ASIC)の速度と電力効率の両方を兼ね備えたものと言うことができます。インテル®™ Aria 10 FPGA PCIeビジョンアクセラレータカード(価格$1500)の消費電力は最大60Wです。
FPGAを使用する上でマイナス面となるのは、FPGAのプログラミングが非常に高度なスキルであることです。FPGAのニューラルネットワークの開発は、非常に複雑で時間もかかります。 開発者はサードパーティ社製のツールを使用してタスクを簡素化することができますが、これらのツールは非常に高額であると同時に、専有技術の閉ざされたエコシステム内に縛られることにもなります。
VPU
視覚処理装置(VPU)は、視覚情報の取得および解析向けに設計されたシステムオンチップ(SOC)の一種です。主にモバイルアプリケーションを念頭に、コンパクト性や電力効率を追求した製品です。インテル® Movidius™ Myriad™ 2 VPUは、視覚処理装置の良い例です。CMOSイメージセンサー(CIS)と連動させて捕捉したイメージデータを事前処理し、結果の画像を事前学習させたニューラルネットワークに送って結果を出力します。この間に消費される電力は、1 W未満です。インテルのMyriad VPUは、従来のCPUコアとベクトル処理コアを組み合わせ、深層ニューラルネットワークに特徴的な分岐論理を加速することにより、これを実現させています。
VPUは、埋め込みアプリケーションには最適です。GPUほど強力ではありませんが、コンパクトで電力効率が高いため、微少なパッケージ内にも構築することが可能です。 例えば、Myriad 2 VPを組み込んだFLIR Fireflyカメラは、標準的な「アイスキューブ」マシンビジョンカメラの半分以下の大きさです。VPUは電力効率が高いため、バッテリー駆動時間が長いことが期待されるハンドヘルドデバイス、モバイルデバイス、ドローン取付け用デバイスには最適です。
インテルは、Movidius Myriad VPUのオープンエコシステムを構築しており、ユーザーが好きなディープラーニングフレームワークやツールチェーンを使ってみることができるようになっています。インテルのNeural Compute StickはUSBインターフェースで、価格は$80です。
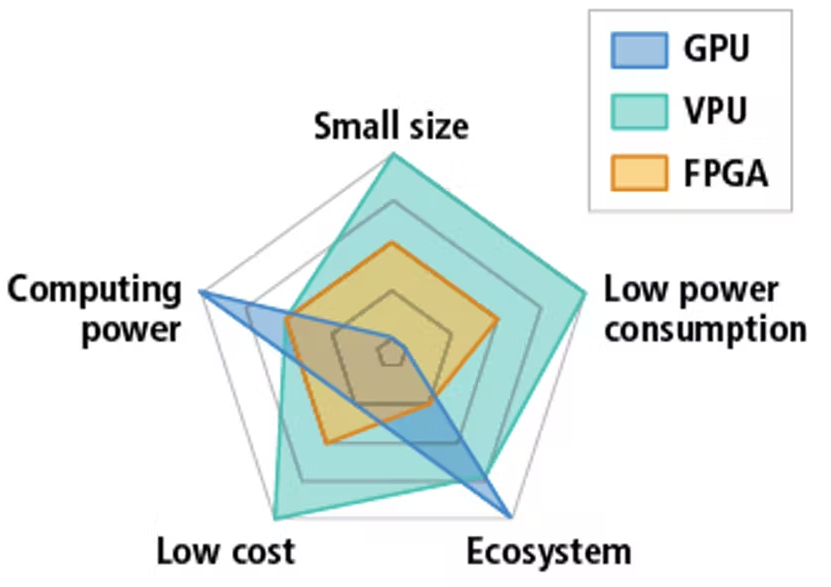
図1推論を高速化するのに使用される一般的なハードウェアの相対的パフォーマンス
様々なハードウェアのパフォーマンスを予測する
GPU、SOC、VPUはそもそもアーキテクチャが異なっているため、浮動小数点演算毎秒(FLOPS)値を使ったパフォーマンスの比較は実際的な意味はありません。公開されている推論速度データの比較は有益であるかもしれませんが、推論速度だけでは正しい結果は導くことができません。シングルフレームの推論速度を比較すると、Nvidia Jetson TX2よりMovidius Myriad 2が速いですが、TX2は一度に複数のフレームを処理できるため、スループットは大きくなります。TX2は他の演算タスクも同時に実行することができますが、Myriad 2はできません。試してみることなくそれぞれを比較するのは簡単なことではないのです。
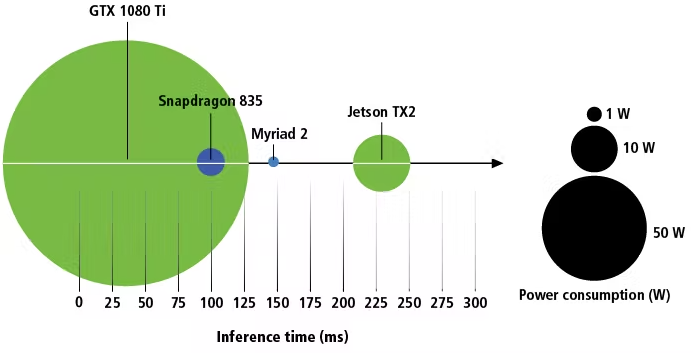
図2電力消費 vs シングルフレームの推論速度
結論
マシンビジョンシステムでの推論をパワーアップするハードウェアを選択する前に、設計者はアプリケーションで必要となる精度や速度を決定するテストを実施する必要があります。これらのパラメータにより、必要となるニューラルネットワークの特徴、およびそのネットワークをデプロイするハードウェアを決定することができるのです。