良好实践:训练深度学习神经网络
简介
深度学习系统效能最重要的决定因素是开发者用于训练的数据集。 高质量的训练数据集在系统资源小、学习进度快时能提高推断的精度和速度。
如果开发者需要通过极端有限的资源在系统中运行深度学习推断,他们可以相应地优化训练过的神经网络并免除对主机系统的需求。 诸如即将推出的 FLIR® Firefly® 相机,这类更小型的设备可在集成的 Movidius™ Myriad™ 2 处理单元上基于部署的神经网络进行推断。
本文将阐述如何开发一个用于分类和排序图像的数据集,这对于刚接触深度学习的用户来说是一个良好的起点。
我需要多少训练数据?
需要的训练数据的数量取决于以下因素:
- 将要区分的数据类的数量,例如 “苹果”、“叶子”、“树枝”。
- 将要区分的类的相似度,例如“苹果”与 “梨子”比 “苹果”与 “叶子”更复杂。
- 各个类内的预期差异,例如不同颜色和形状的苹果,以获得比现实应用场景中更多的差异。
- 图像数据中无用的差异,例如噪声,白平衡、亮度、对比度、物体大小、观察角度的差异等。
几百个图像足以生成可接受的结果,而更复杂的可能需要百万个以上的图像。 确定您训练数据要求的良好方式是收集数据并利用数据测试您的模型。 发现问题,比如 您正在处理的问题,同样可以为估计数据集大小提供很好的起点。
您的网络最终将会达到增加数据已无法继续改进模型精度的程度。 但是不论您的训练数据集有多大,您的模型是不可能达到 100% 的精度。 了解特定应用需要的速度和精度平衡有助于您判断是否需要增加训练数据。
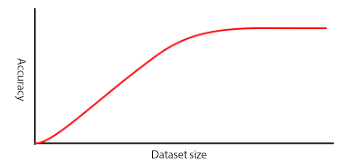
通过验证数据测试
您的图像数据集必须足够大以提供验证数据,验证数据将用于评估网络在训练时的精度和速度 这些图像应随机从数据集中选取,以尽可能地确保其具有代表性。
如果数据集较小或时间和计算能力足够,可通过多重验证确定识别性能。 这里,一个数据集将被分成,例如,五个随机部分。 因此,一个神经网络通过四个部分进行训练,用剩余的一个部分进行验证。 此训练和验证将在全部五种训练和验证部分组合上重复进行。 识别率的平均值表示预期性能。 标准差表示数据集的代表性。
提升您的数据集
深度学习是一个迭代过程。 网络对训练数据进行预测,用于提升网络的性能。 可重复该过程直到网络达到所需精度水平。数据集越大,目标应用赋予深度学习算法的性能差异越高。 过小的数据集无法给算法提供足够信息以使后者正常工作。 因此,您可能会得到较好的训练数据识别性能,但无法在验证数据中获得接近推测概率的识别率。 计划周密的训练数据采集过程可以产生精确标记的图像,且不必要的变异极少,从而降低数据集大小要求,加快训练速度,并提高推断精度和速度。
使训练图像和生成图像间差别最小化
通过相同的相机、光学元件以及后期运行系统将要使用的光照捕捉图像,可免于补偿训练数据集中的几何、照明和光谱响应差别。 配备 Pregius® 传感器、GenICam® 界面和丰富 GPIO 功能的高质量相机可更加简便地自动采集良好的训练数据集。
通过受控环境降低数据集大小
良好的训练数据集包含所需的差异示例,且通过系统设计使差异尽可能最小化。 例如,观察仍然生长在树上的苹果比观察传送带上相同的苹果要复杂得多。 户外系统需要通过训练识别不同距离、朝向、角度的苹果,且必须将不同的光线和天气状况列入考量。 始终一致执行的模型需要很大的数据集。
在受控系统中拍摄苹果图像可以使系统设计者避免许多差异来源并通过小得多的数据集完成高精度推断。 反过来,它也将降低网络规模,使其可在紧凑、单机硬件上运行,例如拥有 Intel Movidius Myriad 2 技术支持的 FLIR Firefly。


图 1. 受控条件下捕捉的图像 (A) 差异性比非受控条件下捕捉的图像 (B) 低。
通过精确标记数据提升训练结果
标记用于测试训练期间的预测。 标记必须代表其归属的图像;不精确或“噪声大”的标记是使用网络搜索收集的数据集的常见问题。 在图像文件名附加标记是一种好思路,因为如此可以在管理和使用训练数据时减少可能的混乱。


图 3. “苹果”类优质图像 (A) 和劣质图像 (B)。
为分部分标记数据比分类更复杂耗时。

图 为分部分标记数据比分类更复杂耗时。
提升已有数据集的质量和数量
通过扩大扩展数据集
类似水果检验这样的系统所检查的物体朝向未经过控制。 对于这些系统,数据扩大作为一种有效方式,可通过仿射和投射转换快速扩展数据集。 颜色转换也可使网络拥有更多图像中。 开发者必须裁切转换后的图像以维持神经网络所需的输入尺寸。

图 5. 转换示例,包括旋转、缩放和剪切。
标准化以提升精度
标准化数据使神经网络训练更加有效。 标准化图像看上去反常,但它们对于训练精确的神经网络更加有效。 开发者可以用同样的方式标准化像素和数值。


图 6. 原始图像 (A) 相比于通过常用 Y = (x - x.mean()) / x.std() (mean 代表均值,std 代表标准差)标准化方式处理后的图像
合成数据
在需要大量数据集扩大无法生成的训练数据时,合成数据是一种强大的工具。 合成数据本质是虚拟成像,虚拟图像可用于快速生成大量预标记且完美分割的数据。 但是,单靠合成数据不足以训练出提供精确、真实结果的网络。 提升合成数据的真实性需要后期处理。
结论
高质量的训练数据集在系统资源小、训练进度快时能提高推断的精度和速度。 同时提升数据集数量和质量有多种办法。 对于希望最小化系统尺寸、实现高精度推断、获取训练数据集并部署神经网络的设计者而言,FLIR Firefly 相机是一个很好的选择。
了解更多信息,请访问 www.flir.com/firefly。